Chroma 是一个开源的向量数据库,专为机器学习和大语言模型(LLM)应用设计,用于高效存储、检索和匹配高维向量数据(如文本、图像等嵌入向量)。
介绍
产生原因:
- 由于当前大模型的 token 数限制,开发者倾向于将数据量庞大的知识(如新闻、文献、语料等)先通过
嵌入(embedding)算法转变为向量数据,然后存储在 Chroma 等向量数据库中 - 当用户在大模型输入问题后,将问题本身同样通过相同 embedding 的算法转化为向量,在向量数据库中查找与之最匹配的相关知识
- 将上述知识,组成大模型的上下文,输入给大模型,获取模型处理结果
- 处理程序最终返回大模型处理后的文本给用户,该方式不仅降低大模型的计算量,提高响应速度,也降低成本,并避免了大模型的 token 限制,是一种简单、高效的处理手段
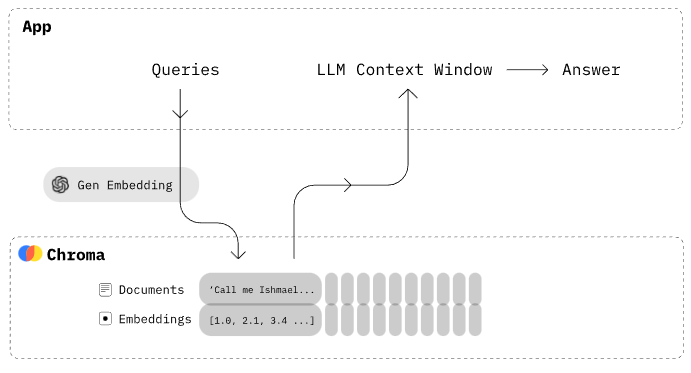
chroma 主要特点
- 轻量级:易于部署,支持本地运行或云端扩展
- 语义搜索:基于向量相似性,快速检索相关内容(例如:搜索语义相近的文本)
- AI 原生:与 OpenAI、Hugging Face 等工具集成,支持构建聊天机器人、推荐系统等
- 灵活接口:提供 Python/JavaScript API,适合开发集成
chroma 功能
- 存储文档数据和对应的元数据:store embeddings and their metadata
- 嵌入:embed documents and queries
- 搜索:search embeddings
服务搭建
- Client-Server Mode,默认监听在 8000 端口
chroma run --path /db_path- docker
echo "allow_reset: true" > config.yaml # the server will now allow clients to reset its state
docker run -v ./chroma-data:/data -v ./config.yaml:/config.yaml -p 8000:8000 chroma-core/chroma使用
chroma 支持 Python 和 JavaScript,下面以 Python 为例介绍如何使用
Python 简单使用
- 安装
pip install chromadb- 使用
chroma-demo1.py
import chromadb
# Create a Chroma Ephemeral Client
chroma_client = chromadb.Client()
# chroma_client = chromadb.HttpClient(host='localhost', port=8000)
# chroma_client = chromadb.PersistentClient(path="/path/to/save/to")
# from chromadb.config import Settings
# chroma_client = chromadb.Client(
# Settings(chroma_db_impl="duckdb+parquet", persist_directory="db/"))
from chromadb.utils.embedding_functions.onnx_mini_lm_l6_v2 import ONNXMiniLM_L6_V2
ef = ONNXMiniLM_L6_V2(preferred_providers=["CPUExecutionProvider"])
# Create a collection
collection = chroma_client.create_collection(name="my_collection", embedding_function=ef)
# Add some text documents to the collection
# switch `add` to `upsert` to avoid adding the same documents every time
# collection.upsert(
collection.add(
documents=[
"This is a document about pineapple",
"This is a document about oranges"
],
ids=["id1", "id2"]
)
# Query the collection
results = collection.query(
query_texts=["This is a query document about hawaii"], # Chroma will embed this for you
n_results=2 # how many results to return
)
print(results)
- 输出
$ python3 python3 chroma-demo.py
/Users/xiexianbin/.cache/chroma/onnx_models/all-MiniLM-L6-v2/onnx.tar.gz: 2%| | 1.91M/79.3M [00:15<13:19, 102
...
{
'ids': [['id1', 'id2']],
'embeddings': None,
'documents': [
[
'This is a document about pineapple',
'This is a document about oranges'
]
],
'uris': None,
'data': None,
'metadatas': [[None, None]],
'distances': [
[1.0404009819030762, 1.2430799007415771]
],
'included': [
<IncludeEnum.distances: 'distances'>,
<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>
]
}- 结果说明
- 返回两个结果,id1(pineapple 与 hawaii 的关联大),排在第一
持久化存储
- 使用
chroma-demo2.py
import chromadb
# Create a Chroma Client
# chroma_client = chromadb.PersistentClient(path="/path/to/save/to")
chroma_client = chromadb.PersistentClient(path="./db")
# chroma_client.heartbeat() # returns a nanosecond heartbeat. Useful for making sure the client remains connected.
# chroma_client.reset() # Empties and completely resets the database. ⚠️ This is destructive and not reversible.
from chromadb.utils.embedding_functions.onnx_mini_lm_l6_v2 import ONNXMiniLM_L6_V2
ef = ONNXMiniLM_L6_V2(preferred_providers=["CPUExecutionProvider"])
# Create a collection
collection = chroma_client.create_collection(name="my_collection", embedding_function=ef)
# Add some text documents to the collection
# switch `add` to `upsert` to avoid adding the same documents every time
# collection.upsert(
collection.add(
documents=[
"This is a document about pineapple",
"This is a document about oranges"
],
ids=["id1", "id2"]
)
# Query the collection
results = collection.query(
query_texts=["This is a query document about hawaii"], # Chroma will embed this for you
n_results=2 # how many results to return
)
print(results)
- 执行后,会自动创建如下文件
$ tree db
db
├── c140b6d1-8448-4f63-b171-9f1e5861090e
│ ├── data_level0.bin
│ ├── header.bin
│ ├── length.bin
│ └── link_lists.bin
└── chroma.sqlite3
2 directories, 5 files- sqlite3 文件如下
$ file db/chroma.sqlite3
db/chroma.sqlite3: SQLite 3.x database, last written using SQLite version 3049001, file counter 55, database pages 41, 1st free page 31, free pages 2, cookie 0x2a, schema 4, UTF-8, version-valid-for 55
$ sqlite3 db/chroma.sqlite3
SQLite version 3.43.2 2023-10-10 13:08:14
Enter ".help" for usage hints.
sqlite> .tables
collection_metadata embeddings
collections embeddings_queue
databases embeddings_queue_config
embedding_fulltext_search maintenance_log
embedding_fulltext_search_config max_seq_id
embedding_fulltext_search_content migrations
embedding_fulltext_search_data segment_metadata
embedding_fulltext_search_docsize segments
embedding_fulltext_search_idx tenants
embedding_metadata
sqlite> select * from collections;
58854d8d-cd83-429b-aae8-4da110628daf|my_collection|384|00000000-0000-0000-0000-000000000000|{"hnsw_configuration": {"space": "l2", "ef_construction": 100, "ef_search": 100, "num_threads": 12, "M": 16, "resize_factor": 1.2, "batch_size": 100, "sync_threshold": 1000, "_type": "HNSWConfigurationInternal"}, "_type": "CollectionConfigurationInternal"}核心概念
Collection: 数据集
# Get a collection object from an existing collection, by name. Will raise an exception if it's not found.
collection = chroma_client.get_collection(name="test")
# Get a collection object from an existing collection, by name. If it doesn't exist, create it.
collection = chroma_client.get_or_create_collection(name="test")
# Delete a collection and all associated embeddings, documents, and metadata. ⚠️ This is destructive and not reversible
chroma_client.delete_collection(name="my_collection")
# returns a list of the first 10 items in the collection
collection.peek()
# returns the number of items in the collection
collection.count()
# Rename the collection
collection.modify(name="new_name")- collection 的元数据 metadata
- 通过 metadata 的
hnsw:space指定距离计算函数,支持l2(默认):Squared L2ip: Inner productcosine: Cosine similarity
- 通过 metadata 的
collection = chroma_client.create_collection(
name="collection_name",
metadata={"hnsw:space": "cosine"} # l2 is the default
)add 方法
- ids: 文档的唯一 ID
- embeddings(可选): 如果不传该参数,将根据 Collection 设置的 embedding_function 进行计算
- 示例中
collection.add没有传入 embedding 参数,默认使用all-MiniLM-L6-v2方式进行embedding
- 示例中
- metadatas(可选):要与嵌入关联的元数据,在查询时,您可以根据这些元数据进行过滤
- documents(可选):与该嵌入相关联的文档,甚至可以不放文档。
def add(ids: OneOrMany[ID],
embeddings: Optional[OneOrMany[Embedding]] = None,
metadatas: Optional[OneOrMany[Metadata]] = None,
documents: Optional[OneOrMany[Document]] = None) -> Nonequery 方法
# 条件搜索
results = collection.query(
query_texts=["This is a query document about hawaii"], # Chroma will embed this for you
n_results=2 # how many results to return
# query_embeddings=[[11.1, 12.1, 13.1],[1.1, 2.3, 3.2], ...],
# n_results=10,
# where={"metadata_field": "is_equal_to_this"},
# where_document={"$contains":"search_string"}
)
# 根据 id 查找
collection.get(
ids=["id1", "id2", "id3", ...],
where={"style": "style1"}
)
# 定制返回结果包含的数据
collection.get({
include: [ "documents" ]
})
collection.query({
queryEmbeddings: [[11.1, 12.1, 13.1],[1.1, 2.3, 3.2], ...],
include: [ "documents" ]
})- where 字段用于按元数据进行过滤
{
"metadata_field": {
<Operator>: <Value>
}
}支持下列操作操作符:
$eq: equal to (string, int, float)$ne: not equal to (string, int, float)$gt: greater than (int, float)$gte: greater than or equal to (int, float)$lt: less than (int, float)$lte: less than or equal to (int, float)
# is equivalent to
{
"metadata_field": {
"$eq": "search_string"
}
}- where_document 字段用于按文档内容进行过滤
# Filtering for a search_string
{
"$contains": "search_string"
}- 可以在查询条件中使用逻辑运算符
{
"$and": [
{
"metadata_field": {
<Operator>: <Value>
}
},
{
"metadata_field": {
<Operator>: <Value>
}
}
]
}
{
"$or": [
{
"metadata_field": {
<Operator>: <Value>
}
},
{
"metadata_field": {
<Operator>: <Value>
}
}
]
}- 使用 in/not in
in 将返回 metadata 中包含给出列表中属性值的文档
{
"metadata_field": {
"$in": ["value1", "value2", "value3"]
}
}not in 则与其相反:
{
"metadata_field": {
"$nin": ["value1", "value2", "value3"]
}
}更新文档
通过 ids 确定要更新的数据,其他参数和 add 方法类似
collection.update(
ids=["id1", "id2", "id3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],
documents=["doc1", "doc2", "doc3", ...],
)删除文档
通过 ids 确定要删除的数据,还允许通过 where 条件进行过滤
collection.delete(
ids=["id1", "id2", "id3",...],
where={"chapter": "20"}
)Embeddings 算法
- Chroma 默认使用的是
all-MiniLM-L6-v2模型来进行 embeddings,更多细节参考:embedding model 介绍
使用示例
- open-webui 使用 chrome 作为向量数据库
- Langchain
F&Q
Unable to compute the prediction using a neural network model.
onnxruntime.capi.onnxruntime_pybind11_state.Fail: [ONNXRuntimeError] : 1 : FAIL : Non-zero status code returned while running 3993270111966163820_CoreML_3993270111966163820_1 node. Name:'CoreMLExecutionProvider_3993270111966163820_CoreML_3993270111966163820_1_1' Status Message: Error executing model: Unable to compute the prediction using a neural network model. It can be an invalid input data or broken/unsupported model (error code: -1). in add.