Influxdb 数据库专题
专栏文章
本文介绍
influxdb的数据库(database)、表(measurements)的概念,增、删、改、查操作。并结合关系型数据库MySQL对比介绍。TDengine可以作为influxdb的替代方案,它还支持 TTL 机制、数据压缩、流式计算等功能,并在性能上有很大的提升。
简介
InfluxDB 是一个开源的时序数据库,使用Rust语言开发,特别适合用于处理和分析资源监控数据这种时序相关数据。而 InfluxDB 自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便。
- https://www.influxdata.com/
- https://docs.influxdata.com/influxdb/
- https://github.com/influxdata/influxdb
influxdb 与 Mysql 对比
库、表比较
| influxDB | 传统数据库中的概念 |
|---|---|
| database | 数据库 |
| measurement | 数据库中的表 |
| points | 表里面的一行数据 |
Influxdb 数据的构成:Line protocol
- Line protocol 参考
Point由时间戳(time)、数据(field)、标签(tags)组成。
# Format
<measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]
# Syntax
measurementName,tagKey=tagValue fieldKey="fieldValue" 1465839830100400200
--------------- --------------- --------------------- -------------------
| | | |
Measurement Tag set Field set Timestamp| Point 属性 | 传统数据库中的概念 |
|---|---|
| timestamp | 每个数据记录时间,是数据库中的主索引(会自动生成) |
| fields | 各种记录值(没有索引的属性)也就是记录的值:温度, 湿度 |
| tags | 各种有索引的属性:地区,海拔 |
measurement表,必须tag_set可索引数据,可选field_set数据,必须timestamp时间戳,可选,默认插入时刻的时间戳point数据点,时间序列中某个时刻的数据series时间序列,serial key 相同的数据集合- 所有在数据库中的数据,都需要通过图表来展示,而这个 series 表示这个表里面的数据,可以在图表上画成几条线:通过 tags 排列组合算出来
series key = measurement + tag + field key- 具体可以通过
SHOW SERIES FROM "表名"进行查询
TICK Stack 组成
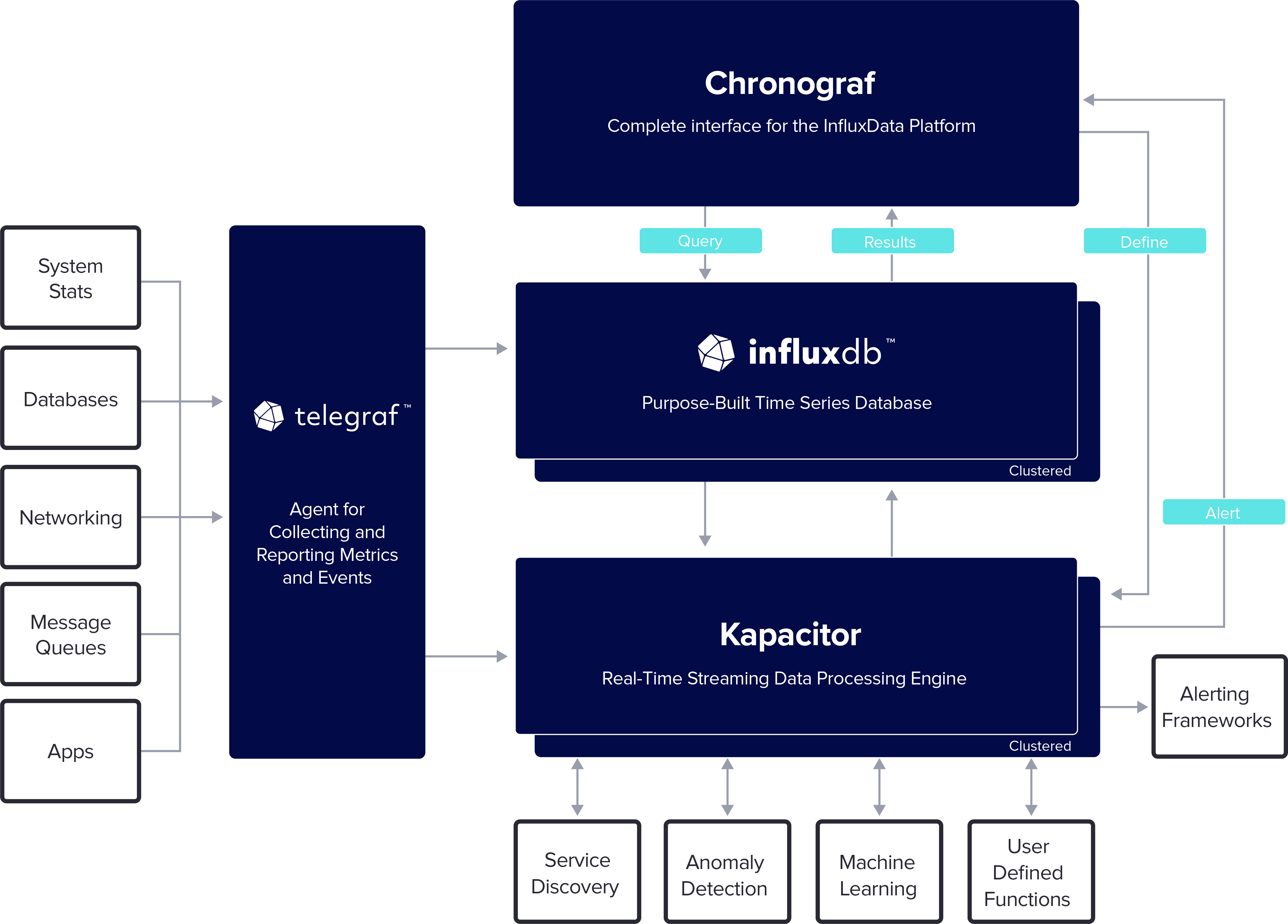
图片摘自
- 数据存储组件 Influxdb:存储时间序列数据
- 收集、报告指标和事件的代理 Telegraf
- 用户界面组件:
ChronografInfluxDB 1.x组件
- 数据处理平台
Kapacitor:实时数据流处理引擎,并向 Chronograf 中创建和发送警报,官网Kapacitor是InfluxDB 1.x的本地数据处理引擎,是InfluxDB 2.0平台的一个集成组件
kapacitor 安装
wget https://dl.influxdata.com/kapacitor/releases/kapacitor_1.6.5-1_amd64.deb
sudo dpkg -i kapacitor_1.6.5-1_amd64.debsudo systemctl start kapacitorKapacitor task 列表:
kapacitor list tasksInflux HA
influx 开源版本不支持 HA,可以通过如下方式实现(针对 v1.x 版本,区别参考):
- influxdb-relay 官方 HA 方案,已不维护
- shell909090/influx-proxy
- chengshiwen/influx-proxy 饿了么开源的高可用方案
- Qihoo360/influx-proxy
- TDengine 替代 influxdb
- 通过 kafka、RabbitMQ 实现数据缓存和多写
influx v2 HA 支持的不太好,可以尝试如下配置:
- Replicate data
- 仅支持 write
- 最大批量大小为 500 kB(通常为 250 至 500 line protocol 行)
应用 & 扩展
- 使用 Telegraf、InfluxDB、Grafana 搭建简单监控步骤
- Chronograf 是 InfluxData 的 TICKScript 的用户界面组件,它提供强大的监控和警报功能
- kapacitor 是一个用于处理、监测和预警时间序列数据的开源框架
参考
- https://docs.influxdata.com/influxdb/v1.6/administration/ports/#enabled-ports
- https://docs.influxdata.com/influxdb/v1.3/introduction/installation/
专栏文章
最近更新
最新评论