NVIDIA GPU 介绍
Linux
GPU(Graphics Processing Unit, 图形处理单元)使用相关介绍
相关术语
- PCIe
CPU(Central Processing Unit)通用目的处理器,逻辑控制能力强,算力相对弱GPU(Graphics Processing Unit, 图形处理器)工作原理,在 CPU 的指挥下工作- GPU 在计算机中相当于一个外部的、专用功能的独立处理设备,通常需要从内存中提交数据到显存,调用显卡的并发计算脚本(从 .cu 编译),再通过从显卡中拷贝计算结果回本地,然后进行下一步计算
- 图片参考
{kind=link}
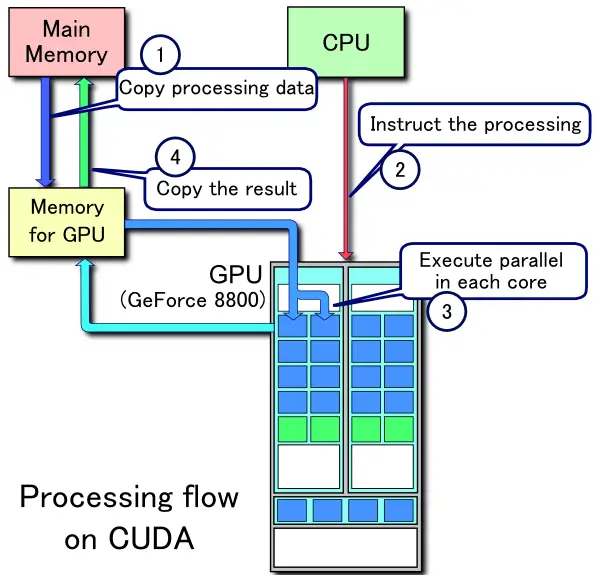
NPU(Neural Processing Unit)硬件实现神经网络运算, 比如张量运算、卷积、点积、激活函数、多维矩阵运算等(参考)TPU(Tensor Processing Unit)功能同上,Google 实现- NVLink
NVSwitch是 NVIDIA 的一款交换芯片,封装在 GPU module 上NVLink Switch是将 NVSwitch 从 GPU module 拆出来的独立设备,跨主机连接 GPU 设备HBM(High Bandwidth Memory)将多个 DDR 芯片堆叠之后与 GPU 芯片封装到一起(参考)- 解决 GPU 显存和普通内存(DDR)在主板上,通过 PCIe 连接到处理器(PCIe 是瓶颈)
NVIDIA Management Library (NVML, NVIDIA 管理库)详情
cuDNN
cuDNN (NVIDIA CUDA® Deep Neural Network library)是NVIDIA专门针对深度神经网络(Deep Neural Networks)中的基础操作而设计基于GPU的加速库。它可以集成到更高级别的机器学习框架中,如 Tensorflow 等。强调性能、易用性和低内存开销。- TensorRT 是 NVIDIA 推出的一套专为深度学习推理打造的 SDK
- 在推理阶段,基于
TensorRT的应用可以提供同比单一 CPU 平台高达 40 倍的加速效果 - 问题:[TensorRT] ERROR: INVALID_CONFIG: The engine plan file is generated on an incompatible device, expecting compute 6.1 got compute 7.5, please rebuild
- 重新进行 TensorRT 模型的转换
- 在推理阶段,基于
NVIDIA 型号
DGX(Deep Learning GPU-Accelerated eXperience)是 NVIDIA 的一款深度学习计算服务器HGX(High-Performance GPU Accelerator)是 NVIDIA 的一款高性能计算服务器(参考)- SXM(Server PCI Express Module) 是一种 high bandwidth socket 解决方案,用于将 Nvidia 计算加速器连接到系统中
- SXM 模块通常用于 NVIDIA 的数据中心 GPU 产品,如 Tesla V100、Tesla A100 等。
- NVIDIA DRIVE Orin SoC(系统级芯片)可提供每秒 254 TOPS(万亿次运算),是智能自动驾驶芯片
DGX A100 拓扑
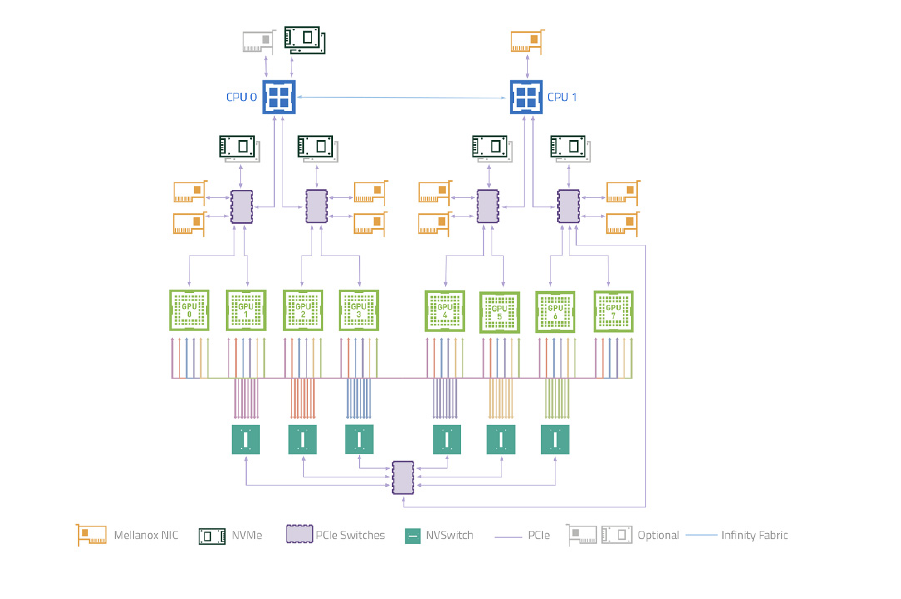
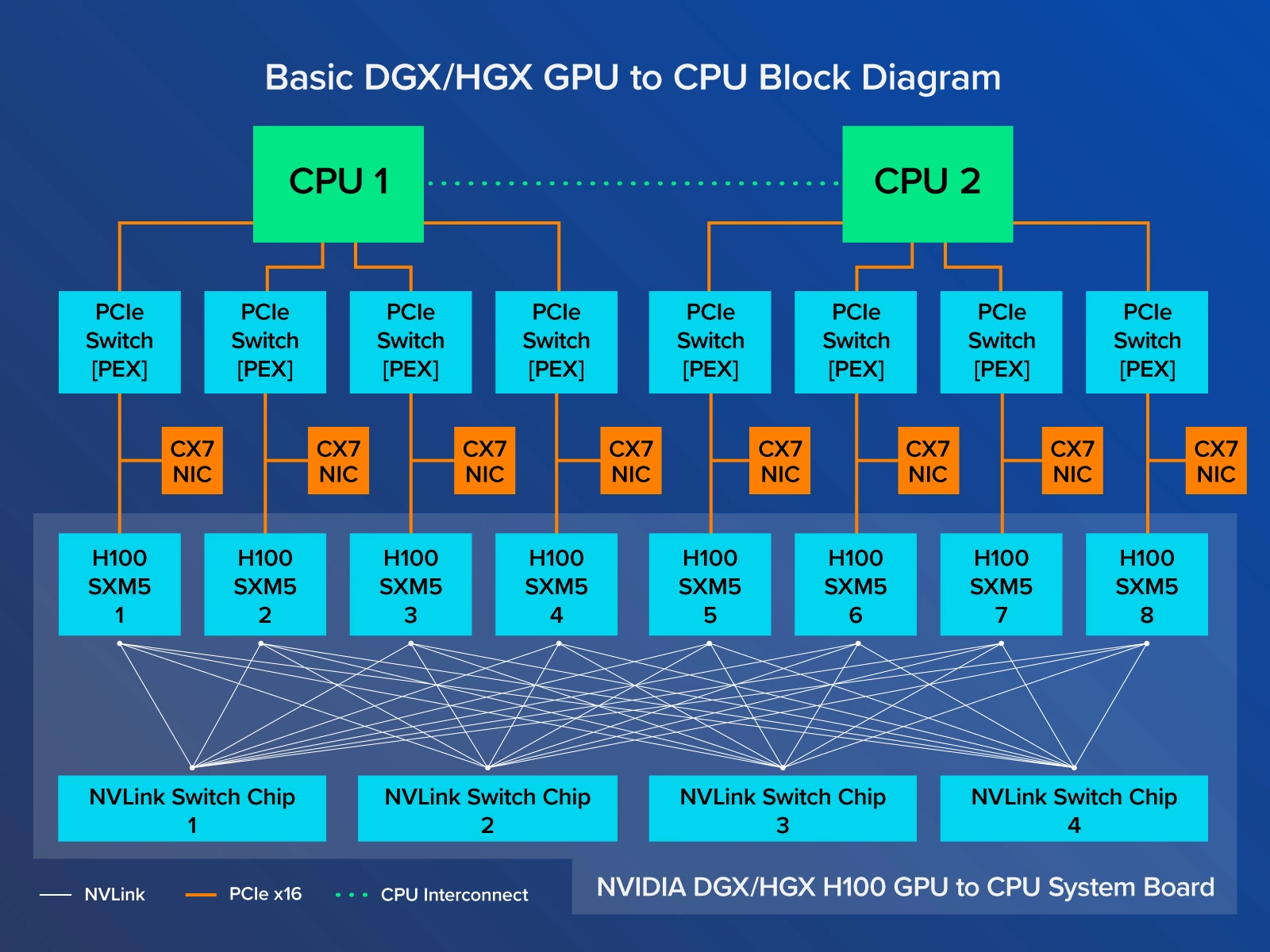
- 上图参考
NVIDIA GPU 查看
- 查看 VGA
$ lspci | grep -i vga
00:02.0 VGA compatible controller: Device 1234:1111 (rev 02)
00:06.0 VGA compatible controller: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] (rev a1)
00:07.0 VGA compatible controller: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] (rev a1)- 查看 nvidia
$ lspci | grep -i nvidia
00:06.0 VGA compatible controller: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] (rev a1)
00:07.0 VGA compatible controller: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] (rev a1)- 显卡详细信息
$ lspci -v -s 00:06.0 # 00:06.0 位置代号
00:06.0 VGA compatible controller: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] (rev a1) (prog-if 00 [VGA controller])
Subsystem: Dell GP102 [GeForce GTX 1080 Ti]
Physical Slot: 6
Flags: bus master, fast devsel, latency 0, IRQ 33
Memory at fc000000 (32-bit, non-prefetchable) [size=16M]
Memory at d0000000 (64-bit, prefetchable) [size=256M]
Memory at f0000000 (64-bit, prefetchable) [size=32M]
I/O ports at c000 [size=128]
[virtual] Expansion ROM at fe000000 [disabled] [size=512K]
Capabilities: [60] Power Management version 3
Capabilities: [68] MSI: Enable+ Count=1/1 Maskable- 64bit+
Capabilities: [78] Express Legacy Endpoint, MSI 00
Kernel driver in use: nvidia
Kernel modules: nvidiafb, nouveau, nvidia_drm, nvidiaVRAM
- 显卡显存
安装 Nvidia Driver
- Nvidia Driver 是在宿主机上安装的驱动程序
- 驱动下载地址:https://www.nvidia.cn/drivers/lookup/
- 禁用系统自带的
nouveau模块
$ lsmod | grep nouveau
$ vim /usr/lib/modprobe.d/blacklist-nouveau.conf
blacklist nouveau
options nouveau modeset=0
$ dracut -force
$ reboot- Install NVIDIA Driver via apt-get(也使用 runfile 安装部署)
# 查看支持的驱动
sudo ubuntu-drivers devices
# 安装驱动
sudo apt-get install nvidia-driver-418 nvidia-modprobe
# 新版本
sudo apt install nvidia-driver-580- 由于 Linux 一切设备皆文件,安装完 Driver 后,可以在 /dev 目录下看到相关文件:
$ ls /dev | grep nvidia
nvidia0 nvidia1 nvidiactl nvidia-uvm nvidia-uvm-tools- 安装完成后,可以使用
nvidia-smi命令 - GPU 驱动卸载
/usr/bin/nvidia-uninstall
或
sudo apt-get --purge remove "*cuda*" "*cublas*" "*cufft*" "*cufile*" "*curand*" "*cusolver*" "*cusparse*" "*gds-tools*" "*npp*" "*nvjpeg*" "nsight*"
# 卸载显卡驱动
sudo apt-get --purge remove "*nvidia*" "cuda*"CUDA samples 程序测试
- BandwidthTest 测试 GPU 卡与主机 server、GPU 与 GPU 卡之间的显存带宽
cd /usr/local/cuda/samples/1_Utilities/bandwidthTest/
make
./bandwidthTest- P2pBandwidthLatencyTest 测试 GPU 卡之间的带宽
cd /usr/local/cuda/samples/1_Utilities/p2pBandwidthLatencyTest/
make
./p2pBandwidthLatencyTest- BatchCuBlas 为 GPU 浮点运算能力测试、加压
cd /usr/local/cuda/samples/7_CUDALibraries/batchCUBLAS/
make
./batchCUBLAS -m8192 -n8192 -k8192 ##默认测试ID号为0的GPU卡
./batchCUBLAS -m8192 -n8192 -k8192 --device=1 ##指定测试ID号为1的GPU卡CUDA
CUDA(Compute Unified Device Architecture,统一计算设备架构)是 Nvidia 提供的一个并发计算平台框架和编程模型,使得使用 GPU 进行通用计算变得简单和优雅CUDA是由英伟达NVIDIA所推出的一种集成技术,是该公司对于GPGPU的正式名称。通过该技术用户可利用NVIDIA的GeForce 8以后的GPU和较新的Quadro GPU进行计算。CUDA可以看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习 GPU 加速库,它就相当于工作的工具,比如扳手。
- CUDA 安装
- https://docs.nvidia.com/deploy/cuda-compatibility/minor-version-compatibility.html
安装 CUDA
# 交互式
sudo chmod +x cuda_12.1.1_530.30.02_linux.run
sudo ./cuda_12.1.1_530.30.02_linux.run
# 非交互式
sudo ./cuda_12.1.1_530.30.02_linux.run --toolkit --samples --silentCUDA卸载
- run 安装
# cuda10.0及以下的卸载
cd /usr/local/cuda-xx.x/bin/
sudo ./uninstall_cuda_xx.x.pl
sudo rm -rf /usr/local/cuda-xx.x
# cuda10.1及以上的卸载
cd /usr/local/cuda-xx.x/bin/
sudo ./cuda-uninstaller
sudo rm -rf /usr/local/cuda-xx.x- deb 包
apt remove 对应的包查看 CUDA 版本
- 检查 CUDA 安装版本
nvcc(Nvidia CUDA Compiler, NVIDIA CUDA编译器)
nvcc -V
# 或
nvcc --version
# 或
cat /usr/local/cuda/version.txt测试 CUDA Samples
cd /usr/local/cuda-12.1/extras/demo_suite
# 显示Result=PASS表示安装成功
./deviceQueryCUDA Toolkit
- CUDA Toolkit包括:
- bin
nvccCUDA 的编译器
- Compiler
- Libraries
- CUDA Samples
- CUDA Driver
- bin
Compute capability
- Compute capability 是 CUDA 和驱动交互时候的一个概念
- PS: PyTorch 的环境变量
TORCH_CUDA_ARCH_LIST="7.0;7.5;8.6"可以指定算力(compute capability),解决RuntimeError: CUDA error: no kernel image is available for execution on the device问题
- PS: PyTorch 的环境变量
测试脚本:
$ echo "Torch Version: $(python -c 'import torch; print(torch.__version__)'), Is CUDA Available: $(python -c 'import torch; print(torch.cuda.is_available())')"
Torch Version: 1.8.1+cu101, Is CUDA Available: True # +cu101 表示是适配 cuda 10.1 的版本cuda 卸载
/usr/local/cuda/bin/cuda-uninstallercuda execution failed with error: 209: no kernel image is available for execution on the device
或错误日志:
RuntimeError: CUDA error: no kernel image is available for execution on the device- 原因:安装的 cuda 和 torch 版本和显卡不适配;算力不匹配
- 参考
- 解决方式:使用环境变量指定
TORCH_CUDA_ARCH_LIST="7.5 8.0"
NVLink
- https://en.wikipedia.org/wiki/NVLink
NVLink(Nvidia Link)是由 NVIDIA 开发的一种高速、低延迟的专有连接技术,主要用于连接 NVIDIA 图形处理器(GPU),提升 GPU 间通信能力



nvidia-smi nvlink 命令
NVLINK 监控指标
- FOR GPU <-> NVLINK (Bps)
- FOR GPU <-> PCI (Bps)
- DCGM_FI_PROF_PCIE_TX_BYTES
- DCGM_FI_PROF_PCIE_RX_BYTES
NVLINK 带宽测试脚本
- A800 机器理论 NVLINK 全互通带宽为 400GB/s,实际测试可达 370GB/s
NCCL
- NVIDIA
集合通信库 (NCCL, Nvidia Collective multi-GPU Communication Library)可实现针对 NVIDIA GPU 和网络进行性能优化的多 GPU 和多节点通信基元。NCCL 提供了 all-gather、all-reduce、broadcast、reduce、reduce-scatter、point-to-point send 和 receive 等例程,这些例程均经过优化,可通过节点内的 PCIe 和 NVLink 高速互联以及节点间的 NVIDIA Mellanox 网络实现高带宽和低延迟 - 环境变量(更多参考)
NCCL_IB_HCA=mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1要使用的环境中 RDMA 网卡NCCL_SOCKET_IFNAME指定用于通信的 IP 接口 设置成主机的 host 网卡,可通过ip a查找,推荐配置为:NCCL_SOCKET_IFNAME=eth1NCCL_IB_DISABLE=0是否关闭 RDMA 通信- 设置成 1 来启用 TCP 通信(非 RDMA),推荐配置为:NCCL_IB_DISABLE=0
NCCL_DEBUG=INFONCCL 日志级别
- 更多 https://developer.nvidia.cn/nccl
NCCL 测试
NCCL(Nvidia Collective Communication Library)是 NVIDIA 的集合通信库,支持安装在单个节点或多个节点的大量 GPU 卡上,实现多个 GPU 的快速通信- NCCL Tests 是一个测试工具集,可以用来评估 NCCL 的运行性能和正确性
wget https://github.com/NVIDIA/nccl-tests/archive/refs/tags/v2.10.1.tar.gz
tar -zxvf v2.10.1.tar.gz
cd nccl-tests-2.10.1
make- 单机性能测试:
# 8 GPUs (-g 8), scanning from 8 Bytes to 128MBytes
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 8
# ./build/all_reduce_perf -b 256M -e 8G -f 2 -g 8 -n 100 -w 20- 相关环境变量
- NCCL_P2P_DISABLE 禁用点对点 (P2P) 传输
- NCCL_P2P_LEVEL 允许用户精细控制何时在 GPU 之间使用点对点(P2P)传输,支持 LOC/NVL/PIX 等
GPUDirect
- GPUDirect 是 NVIDIA 开发的一项技术,实现 GPU 与其他设备(例如网络接口卡(NIC) 和存储设备)之间的直接通信和数据传输,而不涉及 CPU 内存中转
- GPU Direct 技术包括:
GPUDirect Storage允许存储设备和 GPU 之间进行直接数据传输,绕过 CPU,减少数据传输的延迟和 CPU 开销GPUDirect P2P(Peer-to-Peer)参考- 主要用于单机 GPU 间的高速通信,它使得 GPU 可以通过 PCI Express 直接访问目标 GPU 的显存,避免了通过拷贝到 CPU host memory 作为中转,大大降低了数据交换的延迟
- NVLink 是 NVIDIA 于 2016 年发布,解决 PCIe 的带宽瓶颈,加速多个 GPU 之间或 GPU 与其他设备(如 CPU、内存等)之间的通信,通过 NVSwitch + NVLink 实现 GPU 全连接
- NVIDIA 开发的
NCCL(NVIDIA Collective Communications Library)提供了针对 GPUDirect P2P 的特别优化
GPUDirect RDMA结合 GPU 加速计算和RDMA(Remote Direct Memory Access)技术,实现在跨节点 GPU 和 RDMA 网络设备之间直接进行数据传输和通信的能力- GPUDirect 视频
MIG
GPU MIG(Multi-Instance GPU)功能允许 NVIDIA GPU 安全地划分为多达七个独立的 GPU 实例,用于 CUDA 应用程序,为多个用户提供独立的 GPU 资源以实现最佳 GPU 利用率,每个实例均与各自的高带宽显存、缓存和计算核心完全隔离
- 配置
- Enable VT
- Enable IOMMU
- Enable Access Control Services
# 启用 MIG 模式
nvidia-smi -mig 1
# 查看 GPU 实例配置文件
nvidia-smi mig –lgip
# 创建2个ID为5和14的GPU实例
nvidia-smi mig -cgi 5,14
# 列出的GPU实例
nvidia-smi mig –lgi- 更多参考
其他
- nvidia-peermem kernel module,为基于英伟达 InfiniBand 的 HCA(主机通道适配器)提供了对英伟达 GPU 显存的直接点对点读写访问功能
nvidia-smi topo -p2p nStreaming Multiprocessor(SM)
GPU 压力测试
扩展
- 华为 NPG
- AMD Radeon RX 显卡
F&Q
nvidia-smi 执行慢的问题
执行如下命令可以有效提高速度:
sudo nvidia-persistenced --persistence-mode
或
sudo nvidia-smi -pm 1也可以配置在 /etc/rc.local 中,实现开机启动
No CMAKE_CUDA_COMPILER could be found
C++ 依赖 cuda 编译时,错误
CMake Error at CMakeLists.txt:4 (project):
No CMAKE_CUDA_COMPILER could be found.
Tell CMake where to find the compiler by setting either the environment
variable "CUDACXX" or the CMake cache entry CMAKE_CUDA_COMPILER to the full
path to the compiler, or to the compiler name if it is in the PATH.解决方式:
export PATH=/usr/local/cuda/bin:$PATH如何指定 GPU
训练模型时,使用如下变量设置使用的 GPU 编号
export CUDA_VISIBLE_DEVICES=0
export CUDA_VISIBLE_DEVICES=0,1- pytorch 示例
os.environ["CUDA_VISIBLE_DEVICES"] = '0,1' # 一般在程序开头设置Unable to determine the device handle for GPU 0000:06:00.0
解决方式:
- 下电重启
- nvidia 驱损坏,删除重装
参考
- https://cloud-atlas.readthedocs.io/zh-cn/latest/machine_learning/hardware/nvidia_gpu/nvlink/nvidia-smi_nvlink.html
- https://bbs.huaweicloud.com/blogs/401593
最近更新
相关文章
最新评论