Loki 是一个可水平扩展、高可用性、多租户的开源日志聚合系统,其设计灵感来自 Prometheus,由 Grafana Labs 开发,支持与 Grafana 生态组件紧密集成。
介绍
PS:2024 过年期间整理,后参考马哥教育的 Loki 专题再次整理
LokiLike Prometheus, but for logs.- 灵感来自 Prometheus 指标系统
- 以时序数据格式存储日志流,每个日志流由一组时序
labels(标签)进行标识 - 提供类似与 PromQL 的专用日志检索语言 LogQL, Loki’s query language
- 以时序数据格式存储日志流,每个日志流由一组时序
- 与其他日志系统不同,Loki 的设计理念是:
- 只索引日志的元数据:
labels(标签)(就像 Prometheus 标签一样)- 标签通常是主机名、容器名、日志文件名、程序名、日志级别、HTTP 请求方法、HTTP 响应码
日志流(log stream):是由同一组时序标签标识的日志信息,Loki 的日志数据存储为:index(索引)- 对日志数据本身进行压缩,并以
chunks(块)为单位存储
- 只索引日志的元数据:
- 特点
- 可扩展性,微服务化设计,各个组件可独立进行水平扩展
- 多租户,能有效进行日志数据隔离和实施权限控制
- 可插拔、高效存储:支持多种存储后端
AWS S3或谷歌云存储(GCS)等对象存储中,甚至存储在本地文件系统中- 支持根据需求分别为索引和日志选择不同的存储方案
- Prometheus Alertmanager
- Grafana integration,Grafana v6.0 中开始支持 Loki
- 第三方集成
- Loki 不对日志进行全文索引。通过存储压缩的非结构化日志并只对元数据进行索引,Loki 的操作更简单,运行成本更低
- Loki 使用与 Prometheus 相同的标签对日志流进行索引和分组,使您能够使用与 Prometheus 相同的标签在指标和日志之间无缝切换
- Kubernetes Pod 是存储 Kubernetes Pod 日志的最佳选择。Pod 标签等元数据会被自动抓取并编入索引。
与指标数据对比
- 日志内容更丰富
- 体量更大
- debug 日志信息可以详细显示什么时候发生了什么事件
与其他日志系统对比
| Loki | ElasticSearch | |
|---|---|---|
| 存储 | 空间需求量小 | 大 |
| 索引 | 尽可能少的索引日志信息 | 索引整行日志 |
| 查询语言 | LogQL | Kibana 查询语言(KQL),或 Lucene 查询语言 |
| 日志收集器 | Promtail | Logstash/Beats |
| 用户接口 | Grafan | Kibana |
| 成本 | 开销较低(日志数据压缩存储在 S3 等对象存储中)、但索引(仅索引标签元数据)能力较差 | 开销大、提供全文索引 |
PS:对大规模系统应用场景,ES 通常是更好的选择,但另一种兼具二者优势的是使用 ClickHouse 存储的 SigNoz
简单架构
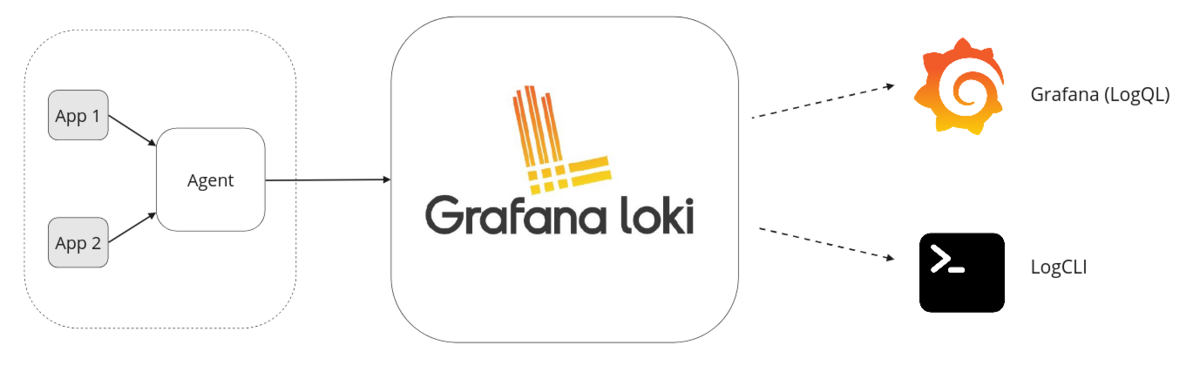
- 参考
- Loki-based logging stack(
PLG(Promtail/Loki/Grafana) Stack) 组成:- 客户端,Loki 支持很多客户端,例如与 Loki 一起发布的
Promtail、Grafana Agent,Docker Driver、Fluentd/Fluent-bit、Logstash 等Promtail负责收集日志并将其发送(Push)给 Loki Server 的 agent,支持发现采集目标(服务发现机制)及添加对应 Label、格式转换和过滤功能- Promtail 是专为 Loki 设计的日志搜集器,请求 HTTP API 以 Push 的方式上传到 Loki
Distributor
Loki Server主服务器,负责接收和存储日志以及处理查询- 不索引日志全文,仅完成标签索引,从而显著降低系统开销及接近实时的查询性能
- LogQL 是 Loki 提供的日志查询语言
- Grafana 可对查询结果进行 WEB 可视化
- HTTP API
- one-shot query
- live streaming
- 专用的命令客户端:logcli
- Grafana 用于查询和显示日志数据
- AlertManager 用户可编写告警规则,并进行周期性评估,超出阈值,由 AlertManager 通知给用户
- 客户端,Loki 支持很多客户端,例如与 Loki 一起发布的
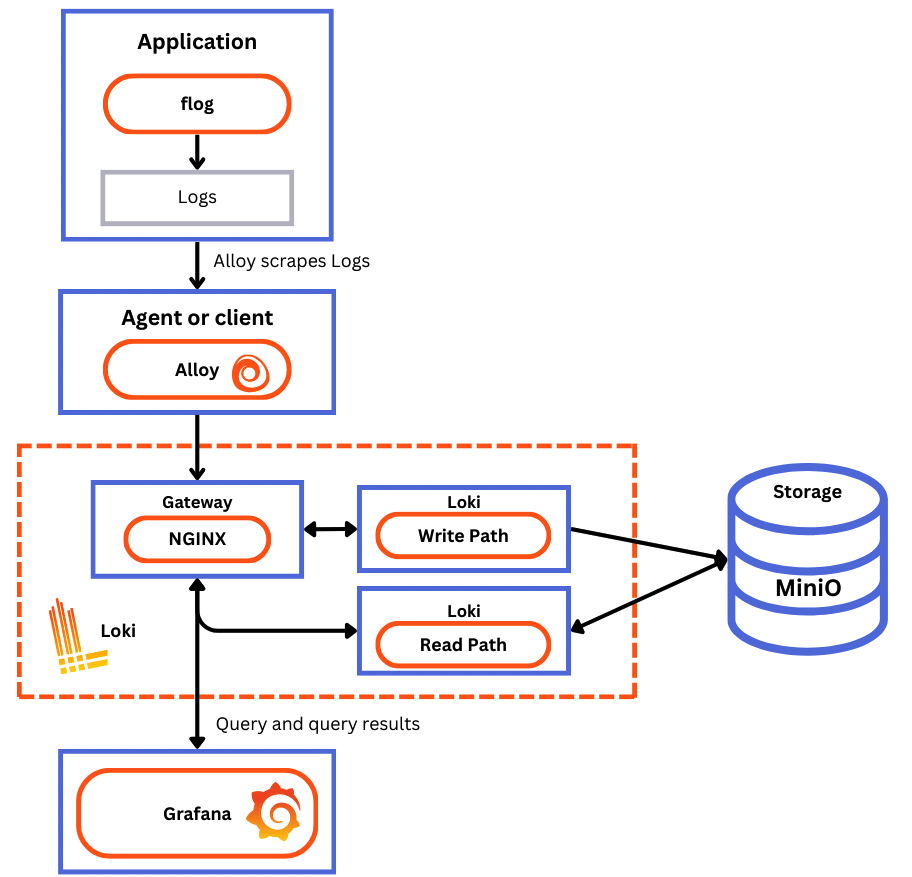
核心组件

- 参考
- Loki 的系统组件大体可以分为两类
Read Path处理读取日志样本请求的组件(参考)Querier基于 HTTP 接收到查询请求- 转发请求到
Ingester来检查缓存在内存中的日志数据 - 若
Ingester查询到了相关数据,则返回给Querier - 若
Ingester为查询到相关数据,则Querier会向存储系统发起请求 Querier基于 HTTP 协议响应查询请求
Write Path处理存储日志样本请求的组件(参考)Distributor基于 HTTP 协议接收到写请求,并将其附加到特定的 streamDistributor将每个 stream 发往IngesterIngester创建一个新Chunk或附加到现有Chunk上Distributor将结果响应给客户端
- 核心组件
Distributor(write path)收到的日志流基于标签进行 consistent hashing 计算后,分发至不同的Ingester,复制因子用于指定要存储的副本数以实现容错- 从 Loki 客户端(如 Promtail)接收数据、检查数据,随后将其分成
数据库(chunks)并发往 Ingester - 无状态应用,可接受 LB 进行数据分发
- shard 数据分片
- Distributor 收到日志流基于标签进行 consistent hashing 计算后,分发至不同的 Ingester,以实现数据分片,从而将写操作负载均衡至多个 Ingester 节点
- 从 Loki 客户端(如 Promtail)接收数据、检查数据,随后将其分成
Ingester(write, read path)- 负责将数据存入外部存储系统(如 s3)以长期存储数据,以及接受客户端的查询请求并响应相关的数据
- 为避免数据丢失,通常应该提供复制式多实例
Compactor将那些由多个Ingester生成的多个索引,以天为单位基于 tenant 合并成单个索引文件,实现高效索引查询Querier(read path)- 处理 LogQL 请求,并从 Ingester 或长期存储系统中加载数据
Querier Scheduler调度查询请求,为Querier Frontend提供更为高级的队列机制,可选组件Querier Frontend(read path)- 处理查询请求的前端组件,如 Grafana
Ruler参考- 告警组件,基于告警规则评估日志数据,并在必要时发送告警通知给 AlertManager
Object Store
loki architecture
数据格式

- 参考
- Loki 日志服务器的时序数据遵循类似 Prometheus 指标的定义规范,所有日志数据都按照时序类型存储
- 时序数据:是在一段时间内通过
重复测量(measurement)获得的观测值的集合
- 时序数据:是在一段时间内通过
- Loki 中的日志存储由两部分组成:
索引数据(index)时序标识日志数据(Chunk)数据样本,时序标识的数据组成的时间线,loki 称为 stream- 每天时间线都有一个唯一的时序标识
- labels 则由一至多组键值对组成
Index format
Loki 会对 chunks 基于 标签集 和 时间范围 进行索引以加快检索操作
- Loki 仅索引日志流的元数据(标签集),不会索引日志内容
- 索引中主要
存储标签集、日志流标识符(stream indentifiers)和时间范围(内部日志流的时间边界) - 索引信息通常存储与 key-value 存储系统中,已提供较快的读取和查询性能,支持的存储包括:
- TSDB (recommended)
- BoltDB (deprecated)
- Loki 对标签命名的限制与 Prometheus 相同
- 支持使用字母、数字、下划线和冒号,且能够匹配 RE2 规范的正则表达式
- 标签不支持使用的字符,需要转化为下划线,例如:标签
app.kubernetes.io/name应写为app_kubernetes_io_name - 注意:
- Loki 有内置动态创建一些标签
- 标签不建议过多,否则导致 Loki 构建一个巨大的索引
- 与 Prometheus 不同,Loki 仅使用标签集(label set)作为时序标识,没有
指标名称
Chunk format
- Loki 会将每个日志流中的日志信息存储为 chunk
- 每个 chunk 存储由特定的时间窗口的日志条目,这些日志条目会被压缩后再进行存储
- 每个 chunk 的所有日志条目会按照 timestamp 进行排序
- chunk 中的内容包括:
压缩的日志条目(compressed log entries)时序信息(time series information)块标识符(chunk identifiers)
- chunks 由
Ingester缓存在内存中,并周期性刷写至磁盘上- 触发刷写操作的条件:达到单个 chunk 的存储上限,或达到窗口时长
- Loki 通常将 chunk 存储在对象存储中,支持的存储包括:
- aws s3 或兼容 s3 协议的存储系统,如 minio、openstack swift、aliyun oss 等
- dynamoDB
- GCS
- BigTable
- Filesystem(single node)
- 支持存储纯文本信息,也支持存储 Json 或 logfmt 格式
- 基于
Log streams(共享同一组标签的日志信息)存储日志数据- 同一 stream 中的数据将会存储在一起,以降低
标签匹配(label matching)可能涉及到的 stream 数量 - 日志信息的匹配将采用类似 grep 式的粗暴方式
- 同一 stream 中的数据将会存储在一起,以降低
- 注意:应尽量小心地避免时间线膨胀的问题
- 时序数据的典型难题之一
cardinality explosion(基数爆炸),即标签上的不同可用值过多
- 时序数据的典型难题之一
----------------------------------------------------------------------------
| | | |
| MagicNumber(4b) | version(1b) | encoding (1b) |
| | | |
----------------------------------------------------------------------------
| #structuredMetadata (uvarint) |
----------------------------------------------------------------------------
| len(label-1) (uvarint) | label-1 (bytes) |
----------------------------------------------------------------------------
| len(label-2) (uvarint) | label-2 (bytes) |
----------------------------------------------------------------------------
| len(label-n) (uvarint) | label-n (bytes) |
----------------------------------------------------------------------------
| checksum(from #structuredMetadata) |
----------------------------------------------------------------------------
| block-1 bytes | checksum (4b) |
----------------------------------------------------------------------------
| block-2 bytes | checksum (4b) |
----------------------------------------------------------------------------
| block-n bytes | checksum (4b) |
----------------------------------------------------------------------------
| #blocks (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| checksum(from #blocks) |
----------------------------------------------------------------------------
| #structuredMetadata len (uvarint) | #structuredMetadata offset (uvarint) |
----------------------------------------------------------------------------
| #blocks len (uvarint) | #blocks offset (uvarint) |
----------------------------------------------------------------------------Block format
-----------------------------------------------------------------------------------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-1 bytes | len(from #symbols) | #symbols (uvarint) | symbol-1 (uvarint) | symbol-n*2 (uvarint) |
-----------------------------------------------------------------------------------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-2 bytes | len(from #symbols) | #symbols (uvarint) | symbol-1 (uvarint) | symbol-n*2 (uvarint) |
-----------------------------------------------------------------------------------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-3 bytes | len(from #symbols) | #symbols (uvarint) | symbol-1 (uvarint) | symbol-n*2 (uvarint) |
-----------------------------------------------------------------------------------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-n bytes | len(from #symbols) | #symbols (uvarint) | symbol-1 (uvarint) | symbol-n*2 (uvarint) |
-----------------------------------------------------------------------------------------------------------------------------------------------参考
最近更新
最新评论