Linux NUMA 介绍
专栏文章
NUMA(Non-Uniform Memory Access,非一致性内存访问)是一种计算机内存的设计方式,不同的内存器件和CPU从属不同的Node,每个Node都有自己的IMC(Integrated Memory Controller,集成内存控制器)。
UMA 架构
UMA(Uniform Memory Access,一致性内存访问) 也称 SMP(Symmetric Multi-Processor,多处理器架构),早期的计算机都会使用 SMP,指所有的CPU都通过同一个Memory Controller访问内存设备。
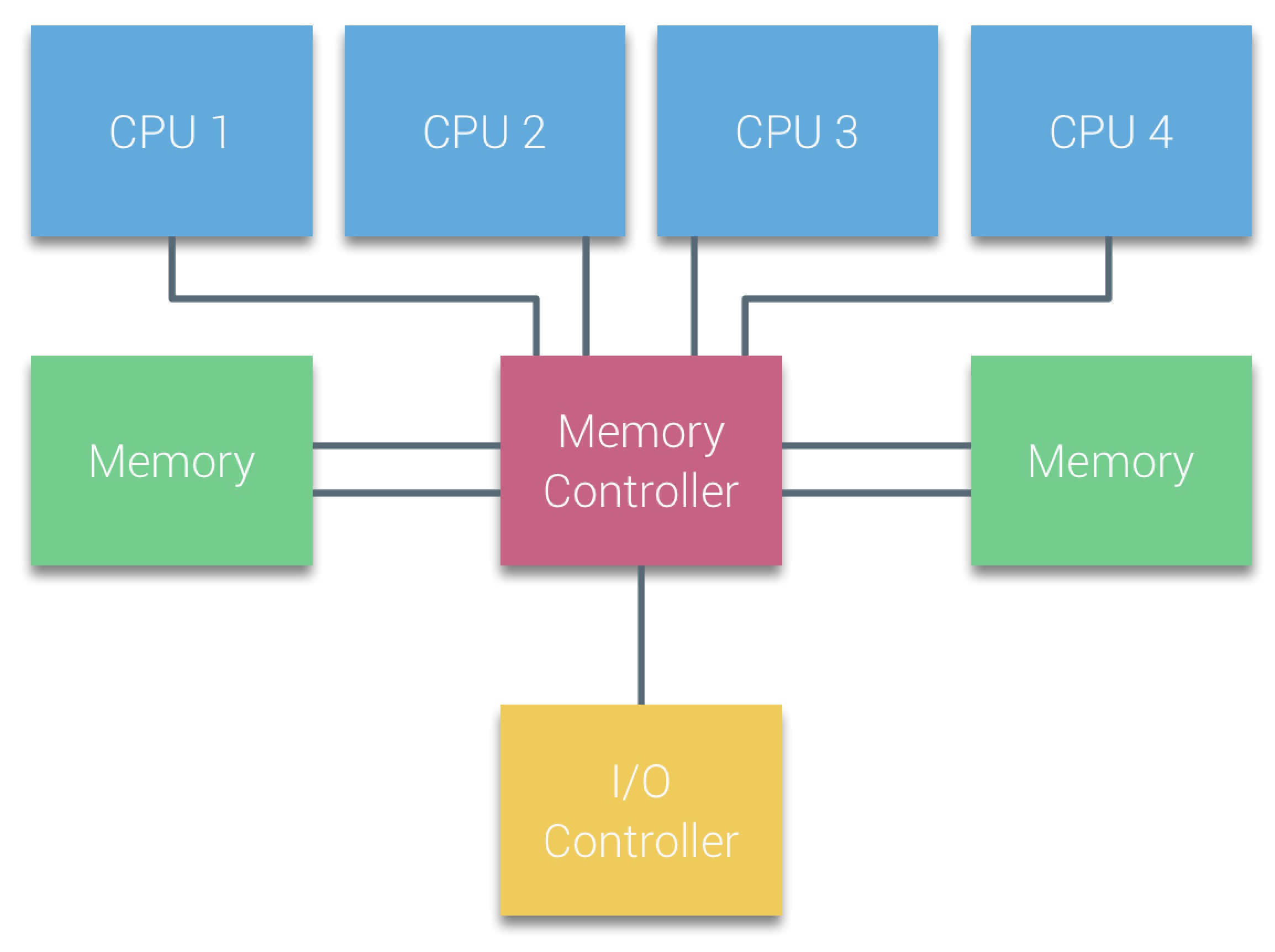
但随着 CPU 核数的不断增多,所有 CPU 都通过总线和北桥访问内存,总线和北桥成为瓶颈,这种架构已经不能满足高性能的需求。因此,现代的多数计算机都会采用 NUMA 架构管理 CPU 和内存资源。
双节点 NUMA 架构
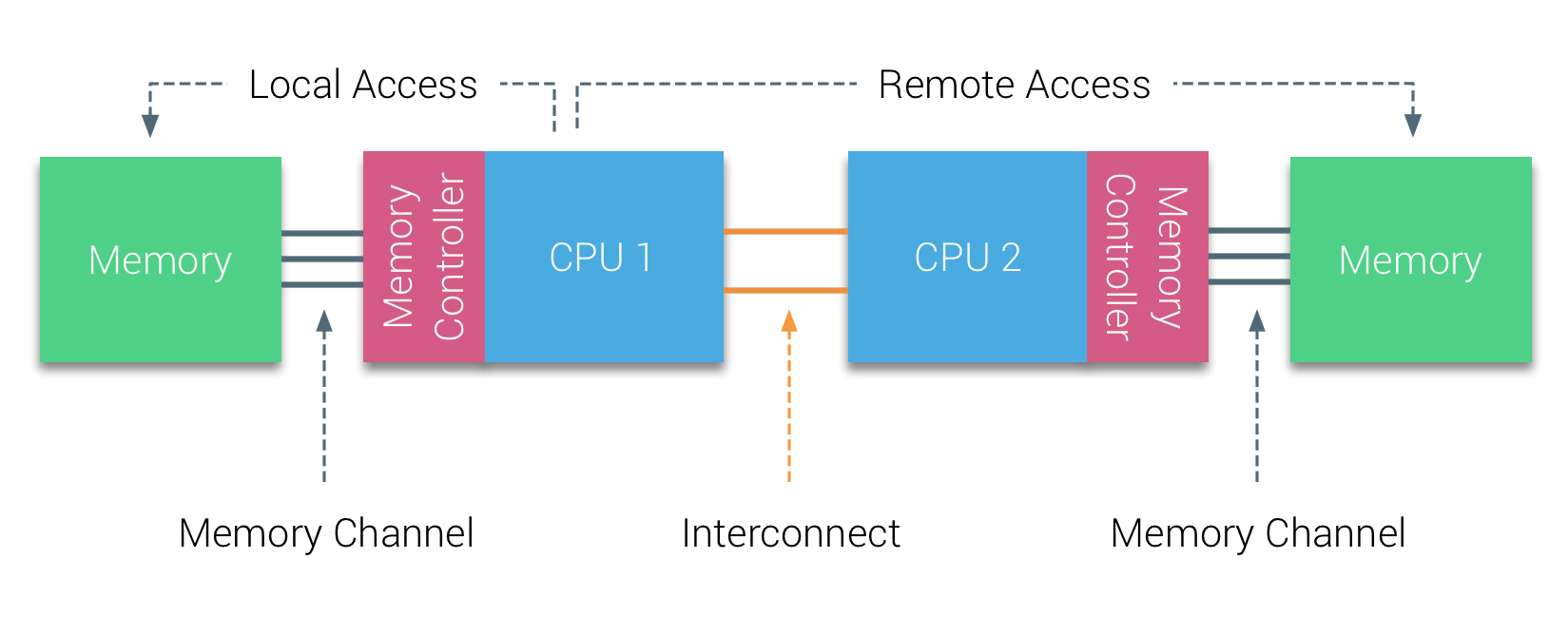
该架构中:
- 由于物理层面的限制,
CPU访问本地内存访问(Local Access Memory)的延迟会小于远程内存访问(Remote Access Memory)
Linux 系统中,NUMA 的信息可以通过 numactl 查看,如下:
$ numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4
node 0 size: 1853 MB
node 0 free: 1558 MB
node 1 cpus: 5 6 7 8 9
node 1 size: 1934 MB
node 1 free: 1561 MB
node distances:
node 0 1
0: 10 20
1: 20 10说明:
- 系统共有2个node,
NUMA node0有4个cpu和1853内存,NUMA node1有4个cpu和1934内存 node distances(距离)说明NUMA node0和NUMA node1互相访问对方内存的延迟是各自节点访问本地内存的 2 倍(20 / 10 = 2),所以如果NUMA node0上的进程在NUMA node1上分配内存,会增加进程的延迟NUMA node访问不同内存的开销不同,在 Linux 系统中,可以使用 numactl 命令控制进程使用的CPU和内存的分配策略
PS:
- 本示例采用
VMWare Fusion模拟,在日志(vmware.log)中可以看到默认没有开启vNUMA功能,默认使用UMA架构
vmx numa: Hot add is enabled and vNUMA hot add is disabled, forcing UMA.当 vCPU 个数大于 8 后,会自动分配 2 个 node。
CPU 分配策略
- cpunodebind : 将进程绑定到指定 NUMA node上
- physcpubind : 将进程绑定到指定物理 CPU 上
内存分配策略
- localalloc : 总是在当前节点上分配内存
- preferred : 默认在指定节点上分配内存,当指定节点的内存不足时,操作系统会在其他节点上分配
- membind : 只能在传入的几个节点上分配内存,当指定节点的内存不足时,内存的分配就会失败
- interleave : 内存会在传入的节点上
依次分配(Round Robin),当指定节点的内存不足时,操作系统会在其他节点上分配
分配示例
在 NUMA node0 上分配 CPU,仅在 NUMA node0 分配内存,当 NUMA node0 上内存不足时,启动失败
numactl --cpunodebind=0 --membind=0 <cmd>参考
专栏文章
- Linux IOMMU 介绍
- Linux NUMA 介绍(当前)
- Linux 使用 isolcpu 参数隔离 cpu
- Linux hugepage 介绍和配置
- Linux 清空缓存 drop caches
- QPS和TPS介绍
最近更新
最新评论