Knative Serving 自动扩缩容系统
请求驱动计算是 Serverless 的核心特性,Knative Pod Autoscaler(KPA)实现 Pod 资源的扩缩。
介绍
Knative 系统中,AutoScaler、Activator 和 Queue-Proxy 三者系统管理应用的规模和匹配流量的规模(通过前面的示例,我们可以看出):
- 缩容至 0:当没有请求时,Knative 不会分配资源给 KServie(缩容为 0)
- 接受扩容事件(请求驱动):当来请求时,由 Activator 缓存请求,并通知 AutoScaler
- 按需扩容:AutoScaler 根据 Revision 中各实例的 Queue-Proxy 报告的调整指标数据动态调整 Revision 中实例的规模
- 也借助底层 k8s 的 Horizontal Pod Autoscaler (HPA) 实现
- 可以通过
kubectl -n knative-serving describe cm config-autoscaler调整相关配置
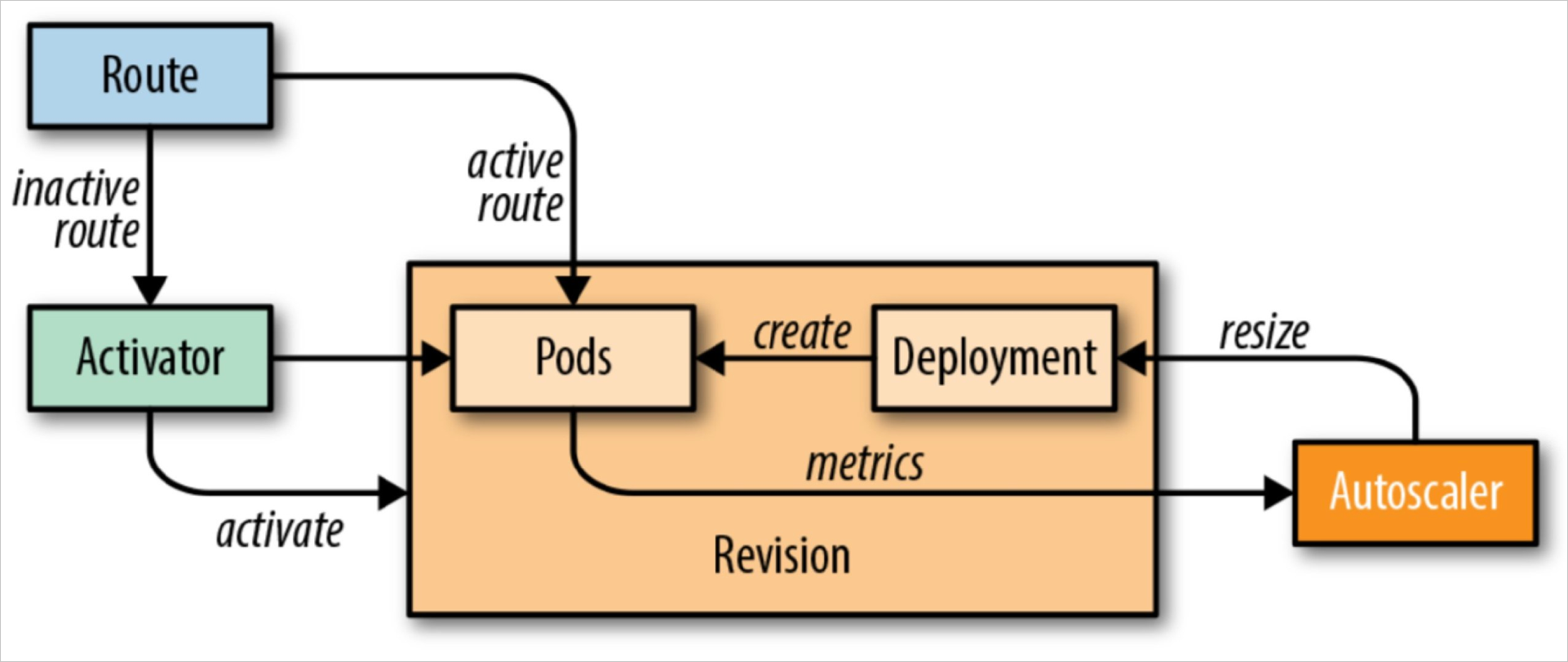
说明:
- 初次请求由 Ingress GW 经 Route 转交给 Activator 进行缓存,同时报告 AutoScaler 进行资源扩缩容
- Pod ok 后,Activator 将缓存的请求转发至对应的 Pod 对象
- 若存在 Ok 的 Pod,Ingress GW 经 Route 直接将流量抓发到对应的 Pod,不经过 Activator 缓存
- 若持续无请求,AutoScaler 根据 Queue-Proxy 的报告一直为 0 时,缩容 Pod 数量为 0
- Activator 在冷启动阶段是 proxy 模式,当当实例足够时,autoscaler 会更新 public service 的 endpoints 指向 revision 对应的 pod,将请求导向真正的后端,这时候处理请求过程中 activator 不在起作用
APIs
PodAutoscaler (PA)
API: podautoscalers.autoscaling.internal.knative.dev
PodAutoscaler 是所有可能的 Pod 自动扩缩容器的一种抽象。默认实现是 Knative Pod Autoscaler (KPA)。还有一个适配器,它通过这种抽象实现了 Kubernetes 的 HPA。
PodAutoscaler 控制扩缩容目标、扩缩容所依据的指标以及与自动扩缩容决策器或收集器相关的任何其他输入。
默认情况下,PodAutoscaler 会根据 Revision 自动创建。
Metric
API: metrics.autoscaling.internal.knative.dev
Metric 本质上是用于控制自动扩缩容器收集器的 API 接口。它控制要抓取哪个服务、如何聚合数据等等。
默认情况下,Metric 会根据 PodAutoscaler 自动创建。
Decider
API: 目前只存在于内存中。此处仅为完整性而提及。
ServerlessServices (SKS)
API: serverlessservices.networking.internal.knative.dev
ServerlessServices 是对 Kubernetes Service 的一种抽象,用于控制数据流,特别是控制两种模式的切换:一种是将 activator 作为数据路径上的缓冲(例如,当扩缩容到零时),另一种是直接将流量路由到应用实例(当扩缩容到零以上时)。
这是通过为每个 Revision 创建两个 Kubernetes Service 来实现的:一个公共服务和一个私有服务。
私有服务是一个标准的 Kubernetes Service。它的选择器被设置为指向已部署的应用实例,随着 Deployment 的伸缩,可用的 IP 列表也会随之变化。
公共服务是一个非托管的 Kubernetes Service。它没有选择器,因此不会像私有服务那样自动进行端点管理。公共服务的端点由 SKS 控制器直接管理。
SKS 有两种模式:Proxy 和 Serve。(ServiceType 代码)
在 Serve 模式下,公共服务的端点与私有服务的端点完全相同。所有流量都将流向 Revision 的 Pod。
在 Proxy 模式下,公共服务的端点是系统中所有 activators 的地址。所有流量都将流向 activators。
ServerlessServices 是根据 PodAutoscaler 创建的。
相关命令查看:
$ kubectl get sks
apiVersion: networking.internal.knative.dev/v1alpha1
kind: ServerlessService
metadata:
annotations:
autoscaling.knative.dev/class: kpa.autoscaling.knative.dev
serving.knative.dev/creator: kubernetes-admin
labels:
app: helloworld-go-xxxxx
serving.knative.dev/configuration: helloworld-go
serving.knative.dev/configurationGeneration: "1"
serving.knative.dev/revision: helloworld-go-xxxxx
serving.knative.dev/revisionUID: xxxxxxxx-xx-xx
serving.knative.dev/service: helloworld-go
name: helloworld-go-xxxxx
namespace: default
...
selfLink: /apis/networking.internal.knative.dev/v1alpha1/namespaces/default/serverlessservices/helloworld-go-xxxxx
spec:
ProtocolType: http1
mode: Proxy # proxy 模式
objectRef:
apiVersion: apps/v1
kind: Deployment
name: helloworld-go-xxxxx-deployment
status:
conditions:
- lastTransitionTime: "xxxx-xx-xxT07:16:32Z"
message: Revision is backed by Activator
reason: ActivatorEndpointsPopulated
severity: Info
status: "True"
type: ActivatorEndpointsPopulated
...
# 查看 ksvc 的 public svc 的 Endpoints 在 Porxy 模式下指向 activator
kubectl describe svc xxx
kubectl describe endpoints xxx
# public svc 代理到服务端口8012、8112
# 此处的 k8s service 没有 label selector,说明这个 service 的后端 endpoint 不是由 k8s 自动控制的,实际上这个 svc 的后端 endpoint 是 由 knative 自己来控制
# private 到指标采集端口8012、8112、9090、9091
kubectl get endpoints <svc-name>[-private]
# 获取 pod id 和运行节点
kubectl -n kourier-system get pod -o wide
# 在gateway运行节点,查看代理的链接情况
ipvsadm -Ln -t <pod-id>:80数据流示例
扩缩容(稳定状态)
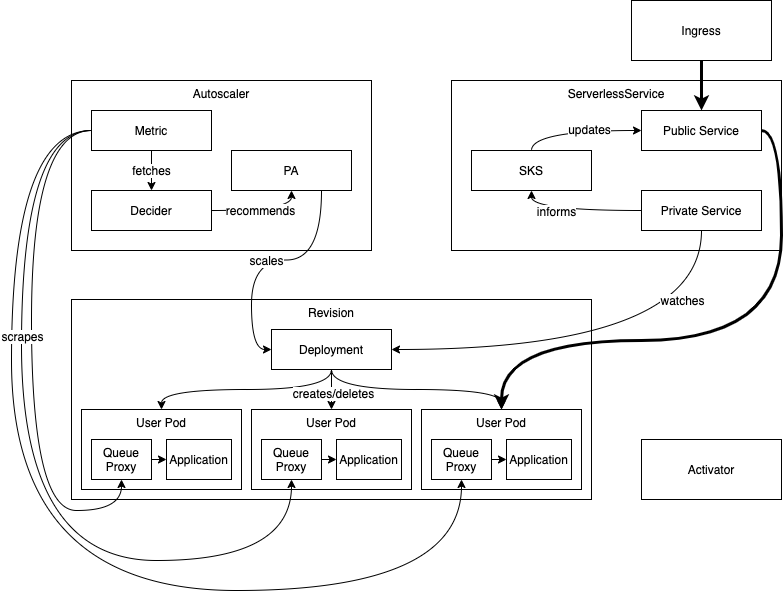
在稳定状态下,自动扩缩容器不断抓取当前活跃的 Revision Pod,以持续调整 Revision 的规模。随着请求流入系统,抓取的值会发生变化,自动扩缩容器会指示 Revision 的 Deployment 遵从给定的规模。
SKS 通过私有服务跟踪 Deployment 规模的变化,并相应地更新公共服务。
扩缩容到零
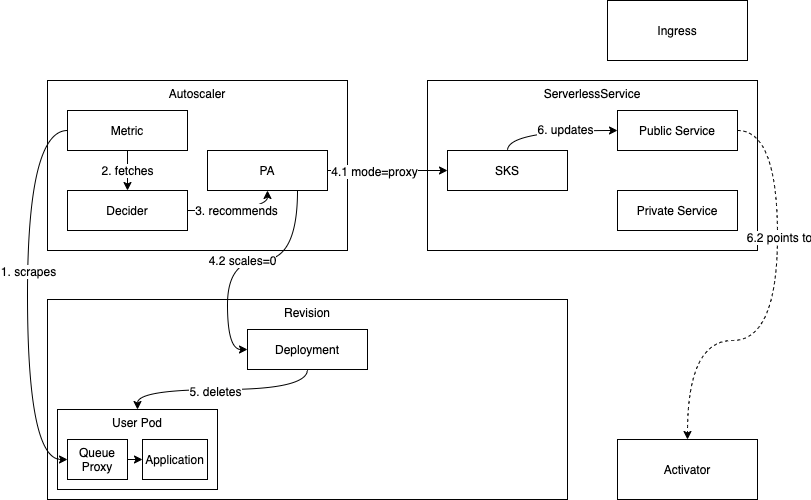
当系统中不再有任何请求时,一个 Revision 就会扩缩容到零。自动扩缩容器对 Revision Pod 的所有抓取都返回 0 并发,activator 报告相同的结果 (1)。
在实际移除 Revision 的最后一个 Pod 之前,系统会确保 activator 处于流量路径上且可路由。首先决定扩缩容到零的自动扩缩容器会指示 SKS 使用 Proxy 模式,以便所有流量都被导向 activators (4.1)。然后,系统会探测 SKS 的公共服务,直到确定它返回来自 activator 的响应。一旦满足此条件,并且宽限期(可通过 scale-to-zero-grace-period 配置)已过,Revision 的最后一个 Pod 就会被移除,Revision 成功扩缩容到零 (5)。
从零扩容
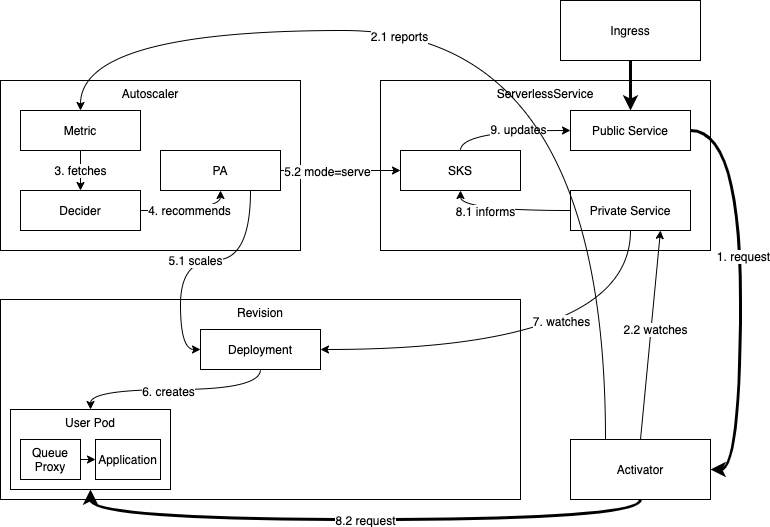
如果一个 Revision 已扩缩容到零,并且有请求进入系统试图访问该 Revision,系统需要将其扩容。由于 SKS 处于 Proxy 模式,请求将到达 activator (1),activator 会对其进行计数并向自动扩缩容器报告其出现 (2.1)。然后,activator 会缓冲该请求并观察 SKS 的私有服务,以等待端点出现 (2.2)。
自动扩缩容器从 activator 获取指标后,会立即运行一个自动扩缩容周期 (3)。该过程将确定至少需要一个 Pod (4),自动扩缩容器会指示 Revision 的 Deployment 扩容到 N > 0 个副本 (5.1)。它还会将 SKS 切换到 Serve 模式,一旦 Revision 的 Pod 启动,流量就会直接流向它们 (5.2)。
activator 最终会看到端点出现并开始探测它。一旦探测成功,相应的地址就会被认为是健康的,并用于路由我们已缓冲的请求以及此期间到达的所有额外请求 (8.2)。
该 Revision 已成功从零扩容。
KPA
Knative Pod Autoscaler(KPA) 基于每个 Pod 的平均请求数(或并发数)进行自动扩缩容,Knative 默认使用基于并发数的自动弹性,每个 Pod 的最大并发数为 100。此外,Knative 还提供了 目标使用率(target-utilization-percentage) 的概念,用于指定自动扩缩容的目标使用率。
基于并发数弹性为例,Pod 数计算方式如为:Pod 数=并发请求总数/(Pod 最大并发数 x 目标使用率)
例如,如果服务中 Pod 最大并发数设置为 10,目标使用率设置为 0.7,此时如果接收到了 100 个并发请求,则 Autoscaler 就会创建 15 个 Pod(即 100/(0.7x10)≈15)。
KPA 基于每个 Pod 的平均请求数(或并发数)来进行自动扩缩容,并结合了 Stable 稳定模式和 Panic 恐慌模式两个概念,以实现精细化的弹性。
|
Panic Target---> +--| 20
| |
| <------Panic Window
| |
Stable Target---> +-------------------------|--| 10 CONCURRENCY
| | |
| <-----------Stable Window
| | |
--------------------------+-------------------------+--+ 0
120 60 0
TIMEStable 稳定模式
在稳定模式中,KPA 会在默认的稳定窗口期(默认为 60 秒)内计算 Pod 的平均并发数。根据这个平均并发数,KPA 会调整 Pod 的数量,以保持稳定的负载水平。
Panic 恐慌模式
在恐慌模式中,KPA 会在恐慌窗口期(默认为 6 秒)内计算 Pod 的平均并发数。恐慌窗口期=稳定窗口期 x panic-window-percentage(panic-window-percentage 取值是 0 ~ 1,默认是 0.1)。当请求突然增加导致当前 Pod 的使用率超过恐慌窗口百分比时,KPA 会快速增加 Pod 的数量以满足负载需求。
在 KPA 中,弹性生效的判断是基于恐慌模式下计算得出的 Pod 数量是否超过恐慌阈值(PanicThreshold)。恐慌阈值=panic-threshold-percentage/100,panic-threshold-percentage 默认为 200,即恐慌阈值默认为 2。
综上所述,如果在恐慌模式下计算得出的 Pod 数量大于或等于当前 Ready Pod 数量的两倍,那么 KPA 将使用恐慌模式下计算得出的 Pod 数量进行弹性生效;否则,将使用稳定模式下计算得出的 Pod 数量。
Knative 中的 Pod 需要多长时间会缩容至 0
Pod 开始缩容至 0 的时间主要取决于 3 个参数:
stable-window:稳定窗口期。Pod 真正缩容前会对此期间内的指标进行观察和评估,而不会立即执行操作。scale-to-zero-grace-period:缩容至 0 的超时时间。在此期间内,即使没有新的请求,系统也不会立即停止或删除最后一个 Pod,以防突发流量请求。scale-to-zero-pod-retention-period:缩容至 0 前最后一个 Pod 的保留时间,以便快速响应突发流量请求,无需从零启动一个新的 Pod。
Pod 缩容至 0 需要满足以下三个条件:
- 首先,在
stable-window内没有收到任何请求。 - 其次,超过
scale-to-zero-pod-retention-period设定的保留时间。 - 最后,SKS(Serverless Kubernetes Service)切换到 proxy 模式的时间超过
scale-to-zero-grace-period设定的时间,Pod 开始缩容。
Pod 缩容至 0 的保留时间不会超过stable-window + Max["scale-to-zero-grace-period", "scale-to-zero-pod-retention-period" ]。如果需要强制为 Pod 设置一个缩容至 0 的保留时间,建议使用scale-to-zero-pod-retention-period参数进行配置。
配置
HPA vs KPA
|
| Knative KPA | k8s HPA | |
|---|---|---|
| 指标类型 | 可以根据 请求量扩速容 | 只能根据 cpu memory 等指标扩缩容(或自定义指标) |
| 01 启动 | 可以缩容到 0 和冷启动 | 只能缩容到 1(如果缩容到 0,就没有实例了,流量进不来,metrics 数据永远为 0,此时 HPA 也无能为力) |
| 指标获取方式 | Knative 指标获取有两种方式,Activator 和 queue-proxy, activator 的 metrics 是通过websocket 主动 push 给 Autoscaler 的,反应更迅速 | k8s 只能是通过 prometheus 轮询获取。 |
| 反应速度 | Knative 默认会 计算 60 秒窗口内的平均并发数, 也会计算 6 秒的恐慌窗口,6s 内达到目标并发的 2 倍,则会进入恐慌模式。在恐慌模式下,Autoscaler 在更短、更敏感的紧急窗口上工作 | 而且 HPA 本身设计比较保守,有一个稳定期(默认 5min)默认在 5min内没有重新扩缩容的情况下,才会触发扩缩容。当大流量突发过来时,如果正处在 5min 内的 HPA 稳定期,这个时候根据 HPA 的策略,会导致无法扩容。 |
- Additional autoscaling configuration for Knative Pod Autoscaler
- Knative Pod Autoscaler (KPA)
- Horizontal Pod Autoscaler (HPA)
configmap/config-autoscaler 配置
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
# 全局并发默认数 100
container-concurrency-target-default: "100"
# 全局并发百分比
container-concurrency-target-percentage: "0.7"
# 修订在创建后必须立即达到的初始目标 需结合allow-zero-initial-scale
initial-scale: "0"
# 只有在使用 KnativePodAutoscaler (KPA) 时才能启用缩放为零
enable-scale-to-zero: "true"
# 放大率 确定所需 Pod 与现有 Pod 的最大比率。例如,具有的值2.0,修改只能从扩展N到2*N
max-scale-up-rate: "1000"
# 缩减率 确定现有 Pod 与所需 Pod 的最大比率。例如,具有的值2.0,修改只能从扩展N到N/2
max-scale-down-rate: "2"
# 扩展到零宽上限时间限制,标志决定了在 Autoscaler 决定将 pod 缩放为零后最后一个 pod 将保持活动状态的最长时间。
scale-to-zero-grace-period: "30s"
# 标志决定了在 Autoscaler 决定将 pod 缩放为零后最后一个 pod 将保持活动状态的最短时间。 "1m5s"
scale-to-zero-pod-retention-period: "0s"
# 自动缩放配置模式--稳定窗口 在缩减期间,只有在稳定窗口的整个持续时间内没有任何流量到达修订版后,才会删除最后一个副本。
stable-window: "60s"
# 自动缩放配置模式--紧急窗口 评估历史数据的窗口将如何缩小例如,值为10.0意味着在恐慌模式下,窗口将是稳定窗口大小的 10%。1.0~00.0
panic-window-percentage: "10"
# 恐慌模式阈值 定义 Autoscaler 何时从稳定模式进入恐慌模式。 流量的百分比
panic-threshold-percentage: "200"
target-burst-capacity: "200"
# 配置每秒请求数 (RPS) 目标
requests-per-second-target-default: "200"
# 每个修订应具有的最大副本数
max-scale: "3"
max-scale-limit: "100"
# 缩减延迟指定一个时间窗口,在应用缩减决策之前,该时间窗口必须以降低的并发性通过。
scale-down-delay: "15m"HPA 配置示例
spec:
template:
metadata:
labels:
app: helloworld-go-hpa
annotations:
autoscaling.knative.dev/class: "hpa.autoscaling.knative.dev" # 指定弹性插件为HPA。
autoscaling.knative.dev/metric: "cpu" # HPA的指标类型可以设置为CPU和Memory。此处以CPU为例。
autoscaling.knative.dev/target: "30" # 设置HPA CPU指标的阈值。根据该阈值,Knative的HPA将自动调整副本数。
autoscaling.knative.dev/minScale: "1" # 设置弹性策略实例数的最小值。
autoscaling.knative.dev/maxScale: "4" # 设置弹性策略实例数的最大值。扩缩容指标配置
可以通过autoscaling.knative.dev/metricAnnotation 为每个 Revision 配置指标,不同的弹性插件支持的指标配置不同。
- 支持的指标:
"concurrency"、"rps"、"cpu"、"memory"以及其他自定义指标。 - 默认指标:
"concurrency"。
Concurrency 并发数指标配置
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: 'concurrency'每秒请求数(RPS)指标配置
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: 'rps'CPU 指标配置
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: 'hpa.autoscaling.knative.dev'
autoscaling.knative.dev/metric: 'cpu'Memory 指标配置
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: 'hpa.autoscaling.knative.dev'
autoscaling.knative.dev/metric: 'memory'扩展
- kedacore/keda 是基于 Kubernetes 的事件驱动的自动化组件
- https://keda.sh/
- 使用 KEDA,可以根据需要处理的事件数量来驱动 Kubernetes 中任何容器的缩放
- KEDA 是一种单活力和轻量级组件,可以添加到任何 Kubernetes 群集中
- KEDA 与标准的 Kubernetes 组件(如水平 Pod Autoscaler)一起工作,可以扩展功能而无需覆盖或重复
- 使用 KEDA,可以明确地映射要使用事件驱动量表的应用程序,而其他应用程序仍在继续运行
- 这使 Keda 成为与许多其他 Kubernetes 应用程序或框架一起运行的灵活和安全的选择