预训练的大语言模型(LLM)可能无法完全满足特定用户需求,因此需要通过微调来提升其在特定任务中的表现。通过微调,模型能够更精准地适应用户的具体应用场景。本文为您介绍微调 LLM 时的策略选择(SFT/DPO)、微调技术(全参/LoRA/QLoRA)以及超参说明,旨在帮助实现模型性能的最佳优化。
SFT/DPO
在 Model Gallery 模块中,您可以对模型进行监督微调(SFT)和直接偏好优化(DPO)训练。大语言模型(LLM)的训练流程通常包括以下三步:
1. 预训练(Pre-Training, PT)
预训练是 LLM 训练流程的第一步,模型在大规模语料库上进行学习,以掌握基本的语法规则、逻辑能力和常识知识。
- 目标:让模型具备语言理解能力、逻辑能力和常识知识。
- 示例模型:Model Gallery 中提供了很多预训练后模型供您使用,如 Qwen 系列、Llama 系列。
2. 监督微调(Supervised Fine-Tuning, SFT)
监督微调是对预训练模型的进一步调整,使其在特定领域的表现更优,适应对话和问答场景。
- 目标:使模型在输出形式和输出内容上表现更优。
- 示例问题:使模型能够专业回答用户特定领域(如中医)的问题。
- 解决方案:准备特定领域(如中医)相关的一问一答形式的数据对模型进行微调。
3. 偏好优化(Preference Optimization, PO)
监督微调后的模型可能会出现语法正确但不符合事实或人类价值观的回复。偏好优化(PO)用于进一步提升模型的对话能力并与人类价值观对齐。主要的方法包括基于强化学习的 PPO(Proximal Policy Optimization)和直接优化语言模型的 DPO(Direct Prefernece Optimization),DPO 使用隐式的强化学习范式,无需显性奖励模型,不直接最大化 reward, 因此在训练上比 PPO 更加稳定。
3.1 直接偏好优化(Direct Preference Optimization, DPO)
- DPO 的模型由两个主要组件构成:一个是需要训练的大型语言模型(LLM);另一个是参考模型,用于防止模型偏离预期。参考模型也是经过微调的大型语言模型,但其参数是冻结的,不会更新。
- 训练数据格式:三元组(prompt,chosen(好的结果 ywin),rejected(差的结果 ylose))
- 损失函数公式如下,从损失函数公式上来看,DPO 算法的原理是让模型在好结果上生成的概率尽量大于 reference model,同时在差结果上生成的概率尽量低于 reference model。
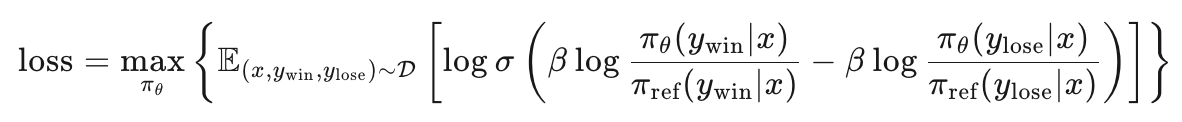
- σ 是 Sigmoid 函数,用于将结果映射到(0, 1)范围。
- β 是一个超参数,通常在 0.1 到 0.5 之间,用于调整损失函数的敏感度。
PEFT: LoRA/QLoRA
参数高效微调技术(Parameter-Efficient Fine-Tuning, PEFT)广泛应用于微调大型预训练模型。其核心思想是在保持大部分模型参数不变的情况下,仅通过微调少量参数来实现具有竞争力甚至领先的性能。由于需要更新的参数量较小,所需的数据和计算资源也相应减少,从而提高了微调的效率。在 Model Gallery 模块中,支持全参微调以及 LoRA、QLoRA 两种高效微调技术:
LoRA(Low-Rank Adaptation)
LoRA 技术通过在模型的参数矩阵(例如 m*n 维)旁边新增一条旁路来实现微调。这条旁路由两个低秩矩阵(m*r 和 r*n 维,其中 r 远小于 m 和 n)相乘而成。在前向传播过程中,输入数据同时通过原始参数矩阵和 LoRA 旁路,得到的输出结果相加。训练过程中,原始参数被冻结,仅对 LoRA 部分进行训练。由于 LoRA 部分由两个低秩矩阵构成,其参数量远小于原始矩阵,因此能够显著减少训练的计算开销。
QLoRA(Quantized LoRA)
QLoRA 结合了模型量化和 LoRA 技术。除了引入 LoRA 旁路,QLoRA 在加载时将大模型量化为 4bit 或 8bit。在实际计算时,这些量化的参数会被反量化为 16bit 进行处理。这样做不仅优化了非使用状态下模型参数的存储需求,还在与 LoRA 相比较时进一步降低了训练过程中的显存消耗。
训练方法选择与数据准备
在选择 SFT 和 DPO 时,请根据您的具体应用场景,参考之前的技术介绍进行决策。
选择全参数训练与 LoRA、QLoRA
- 复杂任务:推荐使用全参数训练,因为它能够充分利用模型的所有参数,从而提升性能。
- 简单任务:建议使用 LoRA 或 QLoRA,这两者训练速度较快且计算资源需求较低。
- 小数据量场景:当数据量较小(几百到小几千条),选择 LoRA 或 QLoRA 有助于防止模型过拟合。
- 计算资源有限:如果计算资源紧张,可以选择 QLoRA 以进一步降低显存消耗。不过需要注意的是,由于增加了量化和反量化的过程,QLoRA 的训练时间可能会较 LoRA 更长。
训练数据准备
-
简单任务:不需要大量数据。
-
SFT 数据需求:经验表明,对于 SFT,数千条数据通常能够达到较好的效果。在这种情况下,数据质量的优化比单纯增加数据量更为重要。
超参介绍
learning_rate
学习率(learning rate)决定了模型在每次迭代中更新参数的幅度。较大的学习率可能加快训练速度,但也可能导致参数更新过度,无法收敛到损失函数的最小值。较小的学习率则提供了更稳定的收敛过程,但可能增加训练时间或陷入局部最优解。使用 AdamW 优化器能有效地防止长期不收敛的问题。
num_train_epochs
epoch 是机器学习和深度学习中的重要概念,1 个 epoch 代表对全部训练数据集进行一次完整的训练。例如设置 epoch 为 10,则模型会遍历全部数据集 10 次来更新训练参数。
epoch 过小可能导致欠拟合,epoch 过大可能导致过拟合。推荐设置 2~10 个 epoch。若样本量少,可增加 epoch 数以避免欠拟合;若样本量大,一般 2 个 epoch 即可。此外,较小的 learning rate 通常需要更多的 epochs。可以通过观察验证集准确率的变化,当其不再提高时,即可终止训练。
per_device_train_batch_size
在实际训练中,我们不会遍历完所有训练数据再对模型参数进行更新,而是使用更小的数据集进行多次迭代,以提高训练效率。batch size 代表每次迭代中使用的训练数据数量。例如设置 batch size 为 32,则每次训练时模型使用 32 个训练数据。参数 per_device_train_batch_size 表示每个 GPU 卡上一次训练使用的数据量。
-
batch size 参数主要用于调节训练速度,不应用于调节训练效果。较小的 batch size 会增加梯度估计的方差,需要更多的迭代才能收敛。增大 batch size 可以缩短训练时间。
-
理想的 batch size 通常是硬件能够支持的最大值
-
保持相同的 per_device_train_batch_size,增加 GPU 卡数,相当于增加总的 batch size。
seq_length
对于 LLM,训练数据经过分词器(tokenizer)处理后,会得到一个 token 序列,sequence length 代表模型接受的单个训练样本的 token 序列长度。如果训练数据的 token 序列长度超过这个长度,数据会被截断;如果小于这个长度,数据会被填充。
在训练时,我们可以根据训练数据的 token 序列长度分布,选择合适的 sequence length。给定文本序列,使用不同的分词器进行处理后,得到的 token 序列长度通常相似,因此我们可以统一使用OpenAI tokens 在线计算工具来估算文本的 token 序列长度。
对于 SFT 算法,请估算 system prompt + instruction + output 的序列长度;对于 DPO 算法,请估算 system prompt + prompt + chosen 和 system prompt + prompt + rejected 的序列长度,并取其中的较大值。
lora_dim/lora_rank
在 Transformer 中应用 LoRA,主要是在多头注意力(multi-head attention)部分进行。有实验表明:
-
适配多头注意力中的多个权重矩阵比仅适配单一类型的权重矩阵效果更佳。
-
增加秩(rank)不一定能涵盖一个更有意义的子空间,一个低秩的适配矩阵可能已经足够。
在 Model Gallery 提供的 llm_deepspeed_peft 算法中,LoRA 适配了多头注意力中的所有 4 种权重矩阵,并且我们提供的默认秩值为 32。
lora_alpha
LoRA 缩放系数,一般情况下取值为 lora_dim * 2。
dpo_beta
在 DPO 训练中使用,控制与参考模型的偏离程度,默认值为 0.1。较高的 beta 值意味着与参考模型的偏离较小。该参数在 SFT 训练中会被忽略。
load_in_4bit/load_in_8bit
在 QLoRA 中使用,分别代表以 4 bit 和 8 bit 精度载入基模型。
gradient_accumulation_steps
较大的 batch size 需要更多的显存,这可能导致 OOM(CUDA out of memory)错误。因此,我们通常设置较小的 batch size。然而,较小的 batch size 会增加梯度估计的方差,影响收敛速度。为了在避免 OOM 的同时提高收敛速度,我们引入了梯度累积(gradient accumulation)。通过在积累多个 batch 的梯度后再进行模型优化,我们可以实现更大的有效 batch size,其值为设置的 batch size* gradient_accumulation_steps。
apply_chat_template
当 apply_chat_template 设为 true 时,训练数据将自动加入模型默认的chat template。如果您希望使用自定义的聊天模板,请将 apply_chat_template 设置为 false,并在训练数据中自行插入所需的特殊标记(special token)。即使 apply_chat_template 为 true,您仍然可以手动定制系统提示(system prompt)。
system_prompt
在 system prompt 中,您可以提供说明、指导和背景信息,以帮助模型更好地回答用户的询问。例如,您可以使用以下 system prompt:“你是一位热情、专业的客服,沟通友好且回答简练,喜欢通过例子来解决用户的问题。”